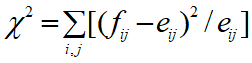Random Forest는 의사결정나무 기반한 ensemble(앙상블) 머신러닝 모델입니다. 앙상블은 여러 Base모델들의 예측을 다수결 법칙또는 평균을 이용해 통합하여 예측 정확성을 향상시키는 방법입니다. 랜던포레스트 배경(양상블) 의사결정나무를 Base모델로 사용하고 있고 다수의 의사결정나무모델을 위한 예측을 종합하는 앙상블 방법이고 하나의 의사결정모델보다 예측 정확도가 높습니다. 1, Btoostrap기법을 이용하여 다수의 training 데이터를 생성 2. traing data로 무작위 변수를 사용하여 Decision tree모델을 구축 3. 예측을 종합 함