분류모형의 성능을 평가하기 위해서는 다양한 명령이 필요하다. 사이킷런 패키지에서 지원하는 분류 성능평가 명령은 다음과 같다.
| 구분 | 사이키런 명령 |
| 분류표 | confusion_matrix(y_true, y_pred) |
| 정확도(Accuracy) | accuracy_score(y_true, y_pred) |
| 정밀도(Precision) | precision_score(y_true, y_pred) |
| 재현율(Recall) | recall_score(y_true, y_pred) |
| 위양성률 | fbeta_score(y_true, y_pred, beta) |
| f1점수 | f1_score(y_true, y_pred) |
| classification_report ( 정밀도, 재현율, F1점수) |
classfication_report(y_true, y_pred) |
| roc커브 | roc_curve |
| AUC(Area Under the Curve) | auc |

분류표
분류표는 아래와 같이 실제값과 예측값을 표로 표시한 것으로, 사이킷런에서는 confusion matrix라고 합니다.
| 실제값( actual) \ 예측값( predicted) | True | False |
| True | 4 | 2 |
| False | 1 | 3 |
|
#분류표
from sklearn.metrics import confusion_matrix
y_true = [0, 0,0,0,1,1,1,0,0,1] #실제값
y_pred = [ 0, 0, 0, 1,1,1,0,0,1,1] #예측값
print(confusion_matrix(y_true, y_pred))
|
평가점수
분류결과는 아래의 4가지 케이스가 있습니다. 아래와 같이 케이스로 성능평가를 할 수 있습니다.
- True Positive(TP) : 실제 True인 정답을 True라고 예측 (정답)
- False Positive(FP) : 실제 False인 정답을 True라고 예측 (오답)
- False Negative(FN) : 실제 True인 정답을 False라고 예측 (오답)
- True Negative(TN) : 실제 False인 정답을 False라고 예측 (정답)
| 실제값( actual) \ 예측값( predicted) | 암이라고 예측 |
암이 아니라고 예측 |
| 실제 암 | 4(TP) | 2(FN) |
| 실제 암이 아닌 경우 | 1(FP) | 3(TN) |
1. 정확도(Accuracy) = (TP + TN) / (TP + TN + FP + FN)
정확도는 가장 직관적으로 모델의 성능을 나타낼 수 있는 평가 지표입니다.
2. 정밀도(Precision)= TP / (TP + FP)
정밀도란 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율입니다. 예측한 클래스 중 실제로 해당 클래스인 데이터의 비율입니다.
3. 재현율(Recall) =TP / (TP+FN)
모델이 실제로 positive인 값들 중에서 몇 %를 검출했는지를 측정합니다. 이는 민감도(sensitivity)라고 부릅니다. 실제 클래스 중 예측한 클래스와 일치한 데이터의 비율입니다.
Precision이나 Recall은 모두 실제 True인 정답을 모델이 True라고 예측한 경우에 관심이 있으나, 바라보고자 하는 관점만 다릅니다. Precision과 Recall은 상호보완적으로 사용할 수 있으며, 두 지표가 모두 높을수록 좋은 모델입니다.
4. 위양성률( Fall-out ) = FP/(FP+TN)
PR(False Positive Rate)으로도 불리며, 실제 False인 data 중에서 모델이 True라고 예측한 비율입니다. 즉, 모델이 실제 false data인데 True라고 잘못 예측(분류)한 것입니다. 이는 특이도(specificity)라 부릅니다.
5. F1 = 2⋅precision⋅recall/(precision+recall)
F1점수는 정밀도와 재현율의 조화평균(harmonic mean) 입니다. Positive와 negative 사이의 불균형이 심할 때 정확도는 의미없는 지표입니다. 따라서 종합적인 값을 주는 지표의 필요성 합니다.
사이킷런 패키지의 metrics 패키지에서는 정밀도, 재현율, F1점수를 구하는 classification_report 명령을 제공합니다. 각각의 클래스를 양성(positive) 클래스로 보았을 때의 정밀도, 재현율, F1점수를 각각 구하고 그 평균값으로 전체 모형의 성능을 평가합니다.
|
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
y_true = [0, 0,0,0,1,1,1,0,0,1] #실제값
y_pred = [ 0, 0, 0, 1,1,1,0,0,1,1] #예측값
print(confusion_matrix(y_true, y_pred))
print(classification_report(y_true, y_pred, target_names=['class 0', 'class 1']))
|

위 classification_report 결과에서 Class0이라고 예측한 데이터의 80%만 실제로 0이었고 1이라고 예측한 데이터의 60%만 실제로 1이었음을 알 수 있습니다. 또한 실제 0인 데이터 중의 67%만 0으로 판별되었고 실제 1인 데이터 중의 75%만 1로 판별되었음을 알 수 있습니다.
ROC와 AUC
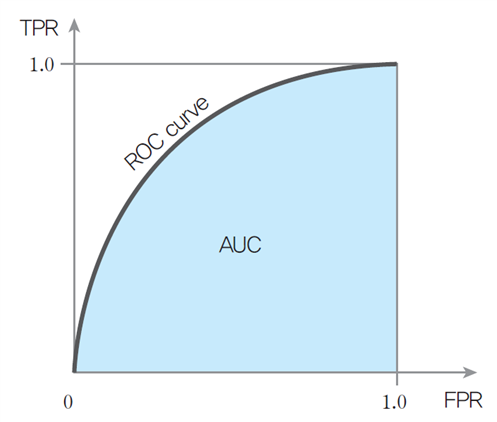
- ROC(Receiver Operator Characteristic) 커브는 클래스 판별 기준값의 변화에 따른 위양성률(fall-out)과 재현율(recall)의 변화를 시각화한 것입니다. 모델이 positive와 negative를 구분하는 임계값(threshold)에 따른 TPR과 FPR을 나타낸 그래프입니다. 민감도와 특이도의 관계가 보이는 양상을 2차원 평면상에 그려낸 것으로 민감도를 높이면 특이도가 낮아지고, 특이도를 높이면 민감도는 당연히 낮아집니다.
- AUC(Area Under Curve)는 ROC Curve의 면적, AUC의 값이 1일 수록 좋은 모델이라 평가합니다.
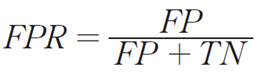
- 허위 양성 비율(False Positive Rate)은 negative 중에서 positive로 잘못 판별한 비율로 위양성률 또는 특이도라고 합니다.
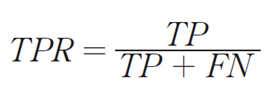
'데이터분석 > 데이터 분류 및 군집화' 카테고리의 다른 글
| 앙상블(Ensemble)의 기본개념 및 Bagging 예제 (0) | 2023.11.15 |
|---|---|
| 의사결정나무를 이용한 분류모형 (0) | 2023.10.25 |
| 중심 기반 군집의 K-Means 군집화 알고리즘 (0) | 2023.10.06 |
| 데이터 계층적 군집화(Hierarchical Clustering) (0) | 2023.10.04 |
| K-Nearest Neighbors 알고리즘 이해과 붓꽃(IRIS) 데이터 활용 (0) | 2023.09.21 |