비지도학습방법으로 유사한 데이터를 N개의 소그룹으로 묶어내는 것을 군집화(clustering)라 합니다. 예를 들어, 신용카드회사에서 고객 소비 데이터를 이용하여 유사한 소비 경향을 군집화하고, 유사 군집(cluster)에 대한 마케팅 활동을 할 수 있습니다.
군집화(Clustering)는
유사한 데이터들의 그룹으로 나누는 것
군집화 종류
| 종류 | 설명 | 알고리즘 에시 |
| 계층적 군집 (Hierarchical Clustering) |
각 군집이 계층을 통해 구분되는 방법 (응집형, 분리형) |
Dendrogram |
| 중심 기반 군집 (Centroid Based Clustering) |
군집(클러스터)의 중심점(centroid)를 정한 뒤 클러스터의 중심점에 가까운 개체들을 하나의 군집으로 모아가면서 확장하는 방법 | K-Means, K-Median, K-medoid |
| 밀도 기반 군집 (Density Based Clustering) |
개체들이 모여 있어 밀도 부분을 하나의 군집으로 분류하는 방법 | DBSCAN (Density-Based Spatial Clustering of Applications with Noise) |
| 확률분포 기반 군집 (Probability Distribution Based Clustering) |
개체들이 어느 군집에 속할 확률이 더 높은지 계산하여 분류하는 기법 | GMM (Gaussian Mixture Model) |
계층적 군집(Hierarchical Clustering)
- 유사성은 두 개체 간의 거리로 거리가 가까울수록 유사하다고 봅니다. 거리는

- 응집형은 나무구조의 잎에서 뿌리로 가는 방법으로 가까운 군집(관측값)끼리 병합하는 방법
- 분리형은 나무주조의 뿌리에서 잎으로 가는 방법으로 먼 관측값(군집)들을 나누어 가는 방법으로 군집을 분할할 경우는 상이한 함수를 사용합니다.
응집형 계층적 군집분석
- Dendrogram은 계층적 군집화를 Tree모양으로 나타낸 그래프로, 가장 많이 사용됩니다.
- Dendrogram 원리
- 모든 개체들 간의 거리(혹은 유사도) 계산해서 행렬(matrix)로 만듦
- 거리가 가장 가까운 개체 두 개를 묶어 하나의 군집화 함
- 만들어진 군집을 포함하여 다시 거리를 계산하여 행렬로 만듦
- 이 과정을 모든 개체가 하나의 군집이 될 때까지 반복함
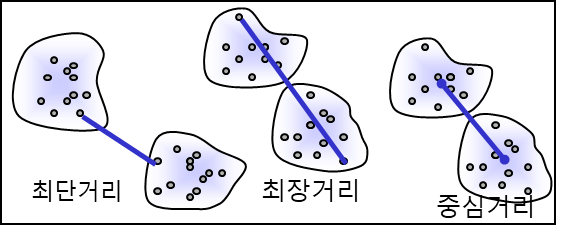
- 병합방법
-
최단연결법
-
최장연결법
-
평균연결법
-
중심연결법
-
Wards 연결법 : 오차의 제곱합이 최소가 되는 군집을 묶어주는 방법
-
iris 데이터를 활용한 실습
- sklearn 패키지에 있는 iris(붓꽃) 데이터를 불러옵니다
|
from sklearn import datasets
import pandas as pd
iris = datasets.load_iris() #iris 데이터를 불러옴
data = pd.DataFrame(iris.data) #iris.data 셑을 데이터 프레임으로 변환
data.columns=['Sepal length','Sepal width','Petal length','Petal width'] #각 컬럼(속성)에 컬럼이름을 부여
data['target'] = pd.DataFrame(iris.target) #taget을 data의 데이터 프레임에 추가함
print(data.head())
|
|
from scipy.cluster.hierarchy import linkage, dendrogram #병합모듈, 데드로그램 모듈을 가지고 옴
import matplotlib.pyplot as plt
mergings = linkage(data,method='ward') #병합방법 ward
|
|
plt.figure(figsize=(20,10)) #이미지 크기 지정
dendrogram(mergings) #계층적 군집을 데드로 그램으로 그림
plt.show()
|
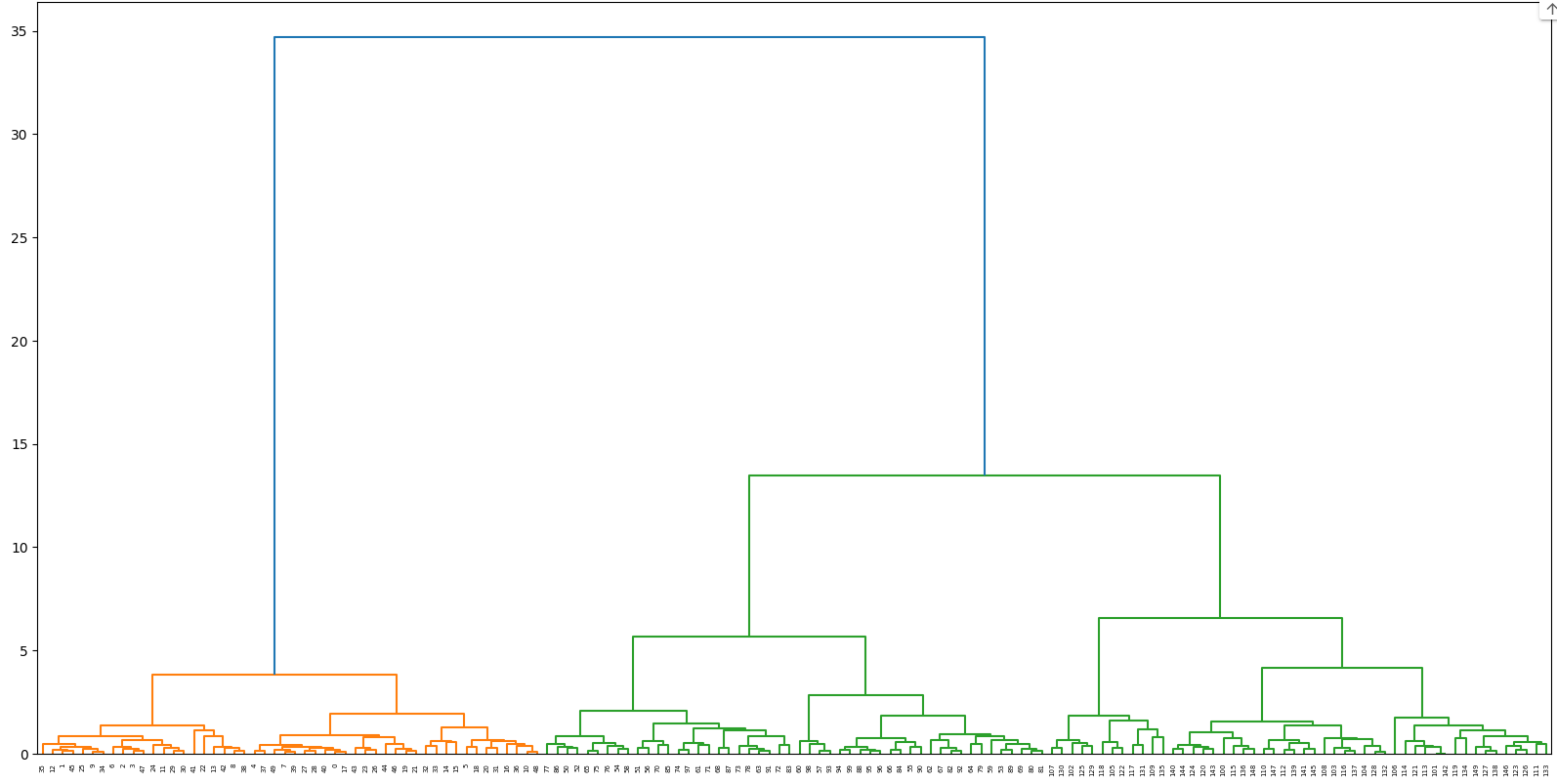
참조 : https://github.com/sense64/data_viz/blob/main/h_clustering_prg1.ipynb
'데이터분석 > 데이터 분류 및 군집화' 카테고리의 다른 글
| 의사결정나무를 이용한 분류모형 (0) | 2023.10.25 |
|---|---|
| 분류모형의 성능평가 (0) | 2023.10.22 |
| 중심 기반 군집의 K-Means 군집화 알고리즘 (0) | 2023.10.06 |
| K-Nearest Neighbors 알고리즘 이해과 붓꽃(IRIS) 데이터 활용 (0) | 2023.09.21 |
| 데이터 분류(Classification)과 군집화(Clustering)의 차이점 (0) | 2023.09.21 |