K-Nearest Neighbors 알고리즘에 대해 이해하고 붓꽃(IRIS) 데이터 활용하여 실습하고자 한다
K-nearest neighbors(K-최근접 이웃) 즉 KNN classification 머신러닝 기법은 분류(Classification) 알고리즘이다. 주변의 가장 가까운 K개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘이 K-NN 알고리즘으로 가까운 거리를 측정할 땐 유클리드 거리(Euclidean distance)를 사용함.
K-Nearest Neighbors 알고리즘을
이용하여
붓꽃 종을 분류하기
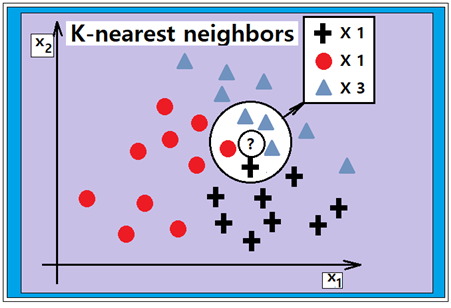
1. KNN 알고리즘 이해하기
K-nearest neighbors(K-최근접 이웃) 알고리즘은 주변의 가장 가까운 K개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘임. K-NN 알고리즘은 이미지 처리, 글자/얼굴 인식, 추천 알고리즘, 의료 분야 등에서 많이 사용됨
- 장점 : 단순하기 때문에 구현하기가 쉬움
- 단점 : 많은 데이터가 필요하며, 데이터 간의 거리를 계산하는 데 시간이 오래 걸림, 분류수 K의 선택이 중요하며, 적절한 K값을 결정하는 데 어려움이 있음
2. 붓꽃(Iris) 데이터 이해하고 활용
붓꽃 데이터는 통계학자 피셔(R.A Fisher)의 붓꽃의 분류 연구에 기반한 데이터로, 사이킷런 패키지에서 제공하는 분류용 예제 데이터임. 붓꽃은 관상용으로 재배되는 꽃으로 크기와 색상이 다른 많은 종(species)이 있습니다

붓꽃의 종은 꽃받침의 길이와 폭 꽃잎의 길이와 폭으로 3가지 종(setosa, versicolor, virginica)으로 구분됨
- 타깃 데이터
- setosa, versicolor, virginica의 세 가지 붓꽃 종(species)
- 특징 데이터
- 꽃받침 길이(Sepal Length)
- 꽃받침 폭(Sepal Width)
- 꽃잎 길이(Petal Length)
- 꽃잎 폭(Petal Width)
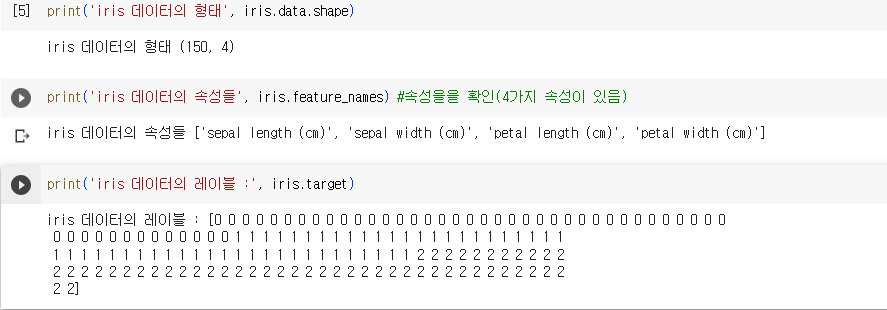
3. IRIS 데이터 탐색
- load_iris() 명령으로 iris데이터를 불러오고, iris data를 출력
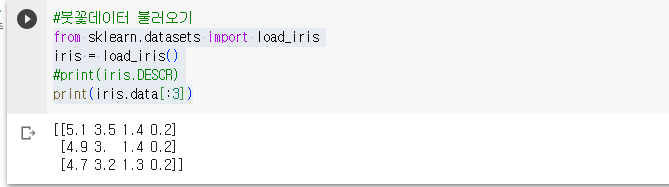
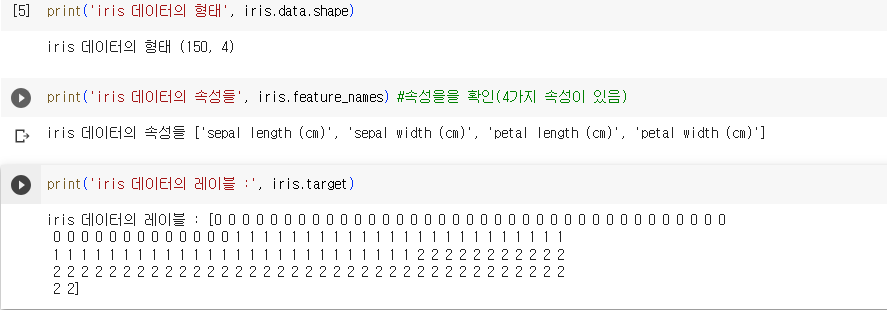
- 데이터의 속성과 형태를 확인
- target데이터는 0:setosa, 1: versicolor, 2: virginica로 확인
4. 데이터프레임으로 변환
iris데이터는 5개의 속성을 가지는데 4개는 iris.data와 다섯 번째 0,1,2 소속 클래스의 값을 갖는 target 속성임(target이 학습에서 사용되는 목푯값)

- describe() : 계량형 데이터의 통계량(요약)을 확인할 수 있음
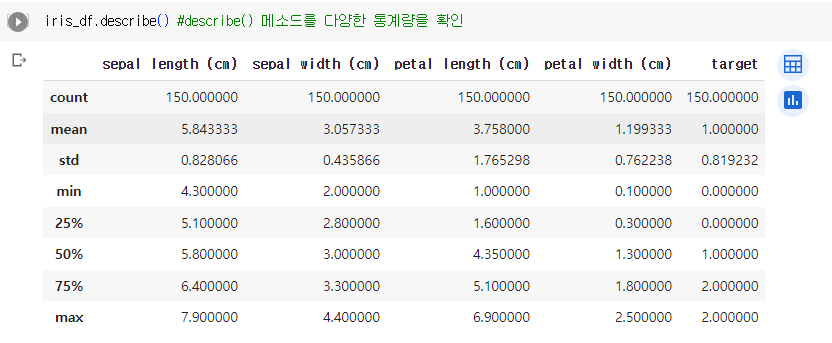
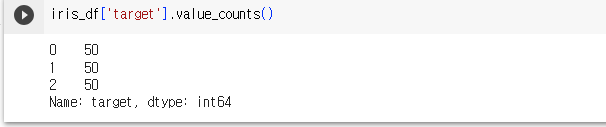
- target 값을 확인하면, 0이 50, 1이 50, 2이 50개 임
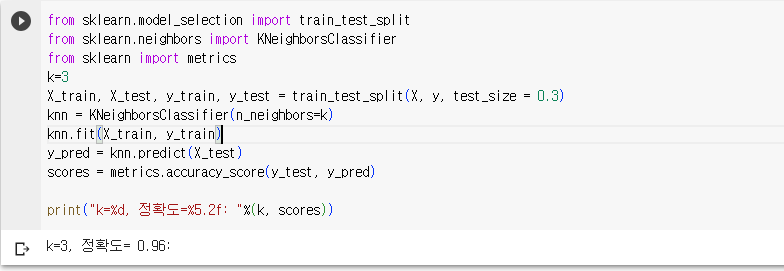
5. 데이터 학습하기
- train_test_split 함수를 사용하여 훈련데이터와 검증데이터로 구분함. X, y라는 데이터에서 X_train, X_test, y_train, y_test로 홀드아웃(테스트용, 훈련용)으로 분류함
- KNN 알고리즘을 사용하기 위해 KNeighborsClassifier 모듈을 호출하고, fit을 이용해서 훈련시키고 모형을 설정
- X_test데이터를 predict(예측) 메서드를 이용하여 예측함
- metrisc.accuracy_score메소를 이용하여 모형을 평가함. 모형의 정확도는 96% 임
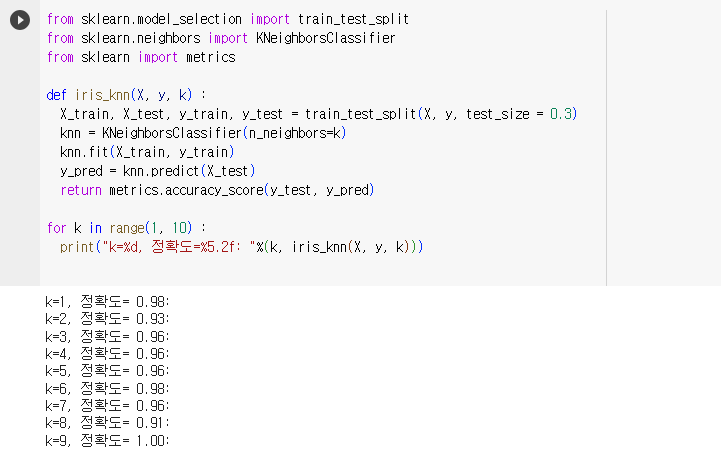
- KNN알고리즘은 분류수 K의 선택이 중요하며, 적절한 K값을 결정하는 데 어려움이 있음
잠깐만 : 분류수를 알아보기 위한 function을 만들어 보고 확인해 보자
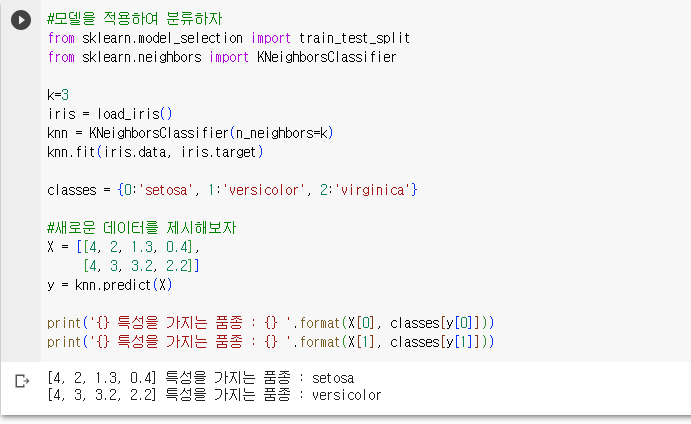
6. 새로운 꽃에 대해 모델을 적용하여 분류
- 모델에 적용을 하면 첫 번째 데이터는 setosa, 두 번째 데이터는 versicolor로 예측함
참고: Scikit-learn 라이브러리는 파이썬의 머신러닝 라이브러리 중 하나인 분류, 회귀분석, 군집화, 의사결정나무 등의 다양한 머신러닝 알고리즘을 적용할 수 있고, 또한 다양한 샘플데이터를 확보할 수 있습니다.
| # 붓꽃데이터 from sklearn.datasets import load_iris iris = load_iris() print(iris.DESCR) #와인데이터 from sklearn.datasets import load_wine wine = load_wine() print(wine.DESCR) #유방암 진단 데이터 from sklearn.datasets import load_breast_cancer cancer = load_breast_cancer() print(cancer.DESCR) #대표 수종데이터 from sklearn.datasets import fetch_covtype covtype = fetch_covtype() print(covtype.DESCR) #뉴스그룹 텍스터 데이터 from sklearn.datasets import fetch_20newsgroups newsgroups = fetch_20newsgroups(subset='all') print(newsgroups.DESCR) #로이터 말뭉치 from sklearn.datasets import fetch_rcv1 rcv = fetch_rcv1() print(rcv.DESCR) #숫자필기 이미지 데이터 from sklearn.datasets import load_digits digits = load_digits() print(digits.DESCR) #올리베티 얼굴 사진 데이터 from sklearn.datasets import fetch_olivetti_faces olivetti = fetch_olivetti_faces() print(olivetti.DESCR) |
'데이터분석 > 데이터 분류 및 군집화' 카테고리의 다른 글
| 의사결정나무를 이용한 분류모형 (0) | 2023.10.25 |
|---|---|
| 분류모형의 성능평가 (0) | 2023.10.22 |
| 중심 기반 군집의 K-Means 군집화 알고리즘 (0) | 2023.10.06 |
| 데이터 계층적 군집화(Hierarchical Clustering) (0) | 2023.10.04 |
| 데이터 분류(Classification)과 군집화(Clustering)의 차이점 (0) | 2023.09.21 |