머신 러닝에서 앙상블이란 단어 그대로 여러 단순한 모델을 결합하여 정확한 모델을 만드는 방법입니다. 분류를 할 때 여러 개의 분류기(Classifier)를 생성하고 여러 모델을 결합하여 최종 예측을 도출하는 기법입니다.
앙상블 학습의 유형은 전통적으로 보팅(Voting), 배깅(Bagging) 그리고 부스팅(Boosting) 이 있습니다.
|
1. 배깅(Bagging)
Bagging(Bootstrap Aggregation)은 샘플을 여러 번 뽑아(Bootstrap) 각 모델을 학습시켜 결과물을 집계(Aggregration)하는 방법입니다. 이때 샘플링은 복원추출*을 합니다. 대표적인 Bagging 방법이 랜덤포레스 알고리즘입니다.

* 복원추출은 한 번 뽑은 데이터를 모집단에 다시 넣어 추출하는 것이고, 비복원추출은 한 번 뽑은 데이터를 모집단에 넣지 않고 샘플링하는 것
- Bagging Classifier
BaggingClassifer 라이브러리를 import 합니다. 베이스모델은 의사결정나무를 하고, 의사결정 나무를 10개를 만들어 모델을 생성합니다. 정확도와 f1_score를 출력을 출력합니다.
- base_estimator: 기본 모형
- n_estimators: 모형 개수. 디폴트 10
- bootstrap: 데이터의 중복 사용 여부. 디폴트 True
- max_samples: 데이터 샘플 중 선택할 샘플의 수 혹은 비율. 디폴트 1.0
- bootstrap_features: 특징 차원의 중복 사용 여부. 디폴트 False
- max_features: 다차원 독립 변수 중 선택할 차원의 수 혹은 비율 1.0
|
from sklearn.model_selection import train_test_split #학습데이터와 검증데이터를 나눔
from sklearn.ensemble import BaggingClassifier #BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, f1_score #모델 평가
X = bank_df.drop('Attrition_Flag', axis=1) #X의 설명변수는 타겟변수를 삭제
y = bank_df['Attrition_Flag'] #y에 타겟변수 지정
#학습데이터와 검증데이터를 나눔
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model=BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators = 10,
max_samples=1.0, max_features=1.0,
bootstrap=True,oob_score=False,random_state=100)
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test,y_pred)
f1 = f1_score(y_test,y_pred,average='macro')
print(f"f1:{f1:4f} accuracy:{accuracy:.4f}")
|
정확도는 94%, f1점수는 89.5%로 나타났습니다.
| f1:0.894665 accuracy:0.9444 |
- Random Forest
의사결정나무를 Base모델로 사용하고 다수의 의사결정나무모델을 Bagging 앙상블 학습 중의 대표적인 것입니다.
|
rf = RandomForestClassifier(random_state=100)
rf.fit(X_train,y_train)
df_pred = rf.predict(X_test)
accuracy = accuracy_score(y_test,df_pred)
f1 = f1_score(y_test,df_pred,average='macro')
acc = accuracy_score(y_test,df_pred)
print(f"f1:{f1:4f} accuracy:{accuracy:.4f}")
|
Random Forest의 정확도는 94.5%, F1점수 89.3%로 위의 BaggingClassifier모듈과 큰 차이가 없습니다.
| f1:0.892570 accuracy:0.9450 |
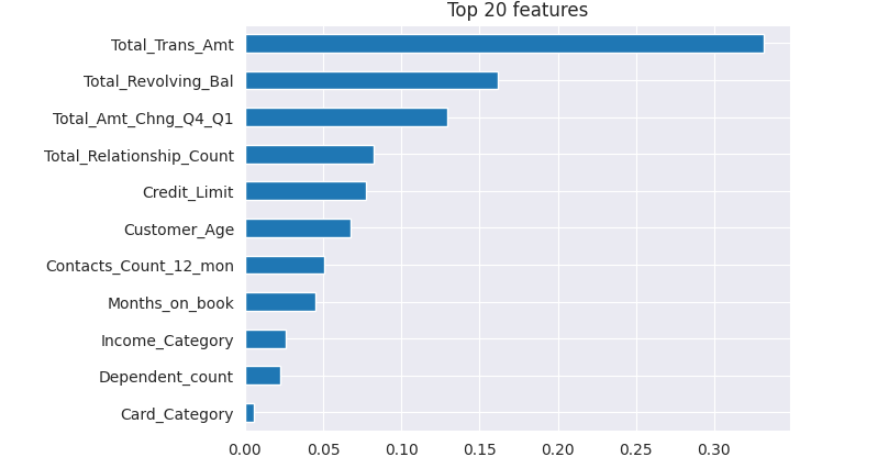
참고) 특성중요도는 각 특성이 모델의 예측에 얼마나 많은 영향을 미치는지를 측정하는 것입니다. 이를 통해 가장 중요한 특성들만을 선택하고 나머지는 무시함으로써 차원을 축소할 수 있습니다. 일반적으로 랜덤 포레스트 같은 앙상블 기반의 모델은 특성 중요도를 제공합니다. 또한, 그래디언트 부스팅 알고리즘 등 다른 알고리즘들도 특성 중요도를 제공합니다.
위의 데이터를 이용하여 랜덤포레스 모델에 대한 특성중요도를 확인하는 프로그램입니다. 그 결과 Total_Trans_Amt의 속성의 가장 중요한 변수이고, 그다음은 Total_Revolving_Bal입니다.
|
rf.feature_importances_ #특성중요도
importances = pd.Series(rf.feature_importances_, X_train.columns)
n=20
plt.title(f'Top {n} features')
importances.sort_values().plot.barh() #var차트를 보여줌
|
2. 보팅(Votting)
Voting에는 Hard Voting과 Soft Voting이 있습니다.

- Hard Voting: 단순 투표. 개별 모형의 결과 기준
- Soft Voting : 가중치 투표. 개별 모형의 조건부 확률의 합 기준
Scikit-Learn의 ensemble 서브패키지는 다수결 방법을 위한 VotingClassifier 클래스를 제공합니다. 입력 인수는 다음과 같다.
- estimators: 개별 모형 목록, 리스트나 named parameter 형식으로 입력
- voting: 문자열 {hard, soft} hard voting과 soft voting 선택. 디폴트는 hard
- weights: 사용자 가중치 리스트
Voting 앙상블의 재현률은 61.7%이고, 의사결정나무는 77.9%입니다.
|
from sklearn.ensemble import VotingClassifier # Voting앙상블 학습
from sklearn.tree import DecisionTreeClassifier #의사결정나무 알고리점
from sklearn.neighbors import KNeighborsClassifier #KNN 알고리즘
# 데이터셋과 데이터나누는 모듈, 정확도 평가 모듈 불러오기
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
dt =DecisionTreeClassifier(criterion='entropy', random_state=2222).fit(X_train, y_train)
knn=KNeighborsClassifier(n_neighbors=2)
vo_clf=VotingClassifier(estimators=[('DT',dt),('KNN',knn)],voting='soft') #의사결정나무와 KNN을 Voting함
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,random_state=2222)
vo_clf.fit(X_train,y_train)
pred=vo_clf.predict(X_test)
print('보팅 분류기 정확도: {0:.4f}'.format(accuracy_score(y_test,pred)))
classifiers=[dt,knn]
for clf in classifiers:
clf.fit(X_train,y_train)
pred=clf.predict(X_test)
class_name=clf.__class__.__name__
print('{0} 정확도: {1:.4f}'.format(class_name,accuracy_score(y_test,pred)))
|

3. 부스팅(Boosting)
부스팅은 오분류된 데이터에 초점을 맞추어 가중치를 활용하여 약 분류기를 강 분류기로 만드는 방법으로, 복원추출 시에 가중치 분포를 고려하며, 오분류된 데이터가 가중치를 크게 되어 다음 round에서 더 많이 고려됩니다. Boosting기법으로는 AdaBoost, Gradient Boosting 등이 있습니다. 부스팅에 관련된 내용은 다음 글에서 제공하고자 합니다.
'데이터분석 > 데이터 분류 및 군집화' 카테고리의 다른 글
| 서포트 벡터 머신(SVM)을 활용한 분류모형 (0) | 2023.11.24 |
|---|---|
| Random Forest와 XGBoost(eXtreme Gradient Boosting) (0) | 2023.11.15 |
| 의사결정나무를 이용한 분류모형 (0) | 2023.10.25 |
| 분류모형의 성능평가 (0) | 2023.10.22 |
| 중심 기반 군집의 K-Means 군집화 알고리즘 (0) | 2023.10.06 |