반응형
1. Planning
- 이해하기
- 의과대학생들의 우울증이 심각한 상태
- 학교를 이탈하는 경우가 다수 발생함
- 환자들의 대면서비스에 대한 불만이 다수 발생
- 프로젝트 개요
- 울증에 영향을 주는 요인과 대체 방안 찾기
- 요인을 찾아 의과대학생들의 이탈율을 방지하고자 함
- 데이터 이해
- 스위스 의과대학 학생들의 empathy(공감), mental health(정신 건강), burnout(탈진) 데이터를 측정한 내용
- Maslach Burnout Inventory (MBI)는 직업적인 환경에서의 감정적, 정신적, 물리적으로 과도한 스트레 스와 업무스트레스로 인한 "소진" 상태를 평가하기 위한 표준화된 도구임(캐글에서 Medical Student Mental Health를 가공함)

2. 데이터 전처리
(1) Data 불러오기
|
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('/content/drive/MyDrive/2024년/data/Data Carrard et al. 2022 MedTeach_raw.csv')
df.info()
|
(2) 결측치를 확인
결측치가 있다면 결측치 처리하는 방법은 다양하지만, 일반적으로 많이 활용되는 방식은 다음과 같습니다.
- 결측치 사례를 제거 : drop() 함수 사용
- 한 행이 모두 missing value이면 제거하려면 df.dropna(how='all').head()
- 한 행에서 하나라도 missing value가 있으면 제거하려면 df.dropna(how='any').head()
- 계량형 데이터 인 경우는 평균값 및 중앙값으로 대체
- 예측모엘로 대체하는 방식
|
df.dropna(how='any', inplace=True) #inplace가 True인 경우 원본의 결측치가 삭제되고 수정됨
|
(3) 범주형 데이터 변형
|
#datatype 변경: astype(데이터형)
df['year']=df['year'].astype(str)
df['sex']=df['sex'].astype(str)
df['psyt']=df['psyt'].astype(str)
df['job']=df['job'].astype(str)
df['glang']=df['glang'].astype(str)
|
df.types로 전체 데이터 형을 확인한다. 범주형데이터는 object로 표시됩니다.

3. 데이터 탐색
데이터 척도에 따라 기술적 분석은 구분 됩니다
- 범주형 데이터는 표와 그림으로 정리요약을 할 수 있습니다.
- 계량형 데이트는 표, 그림 그리고 숫값(대푯값, 산포도)으로 정리요약할 수 있습니다.
우선 데이터를 탐색하기 위해서 계량형데이터와 범주형 데이터로 구분하여 데이터 셑을 생성합니다.
|
df_num=df.select_dtypes(include=[np.number]) #게량형 데이터만 추출하여 df_num으로 생성
df_num.head()
|
|
df_cat=df.select_dtypes(include=[object]) #범주형 데이터만 추출하여 df_cat로 생성
df_cat.head()
|
(1) 1차원 범주형 데이터
- 1차원 범주형 데이터 표로 정리요약은 value_counts() 메서드를 사용하면 빈도를 구할 수 있고, vlaue_counts( normalize=True) 은 비율을 구할 수 있습니다.
|
#범주형데이터를 도수분포표로 확인함
print(df['sex'].value_counts()) #도수
print(df['sex'].value_counts(normalize=True)) #비율
|

- 반복문을 이용하여 모든 범주형 데이터의 빈도분석을 한꺼번에 처리할 수 있습니다. 결과를 보고, 데이터를 수정할 것이 있는지 확인해 봅니다.
|
#범주형데이터 분석(표로)
#반복문을 이용하여 모든 범주형 데이터의 빈도분석을 한꺼번에 처리
for col in df_cat.columns :
print(col)
print(df[col].value_counts())
print(df[col].value_counts(normalize=True)*100)
print("=================================")
|
(2) 1차원(일변량) 계량형 데이터
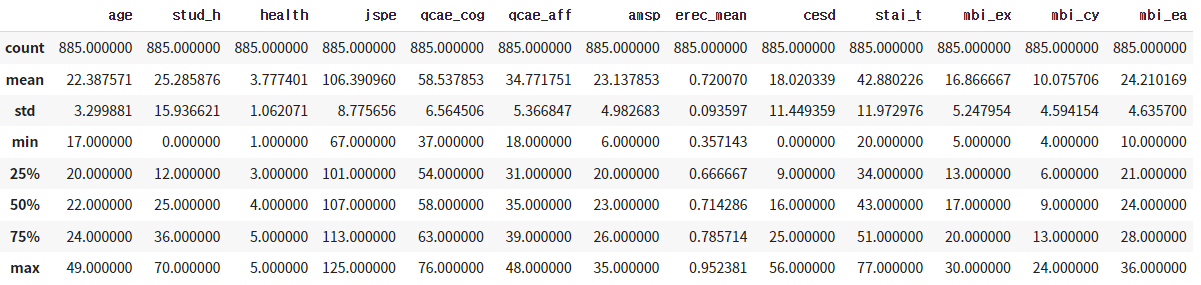
- 1차원 계량형 데이터는 숫값으로 정리 요약은 describe() 함수를 사용하면 됩니다. 아래의 결과를 살펴보면 평균, 표준편차, 최솟값, 제1사분위수, 제2사분위수, 제3사분위수, 최댓값을 확인할 수 있습니다.
| df_num.describe() |
(3) 2차원(다변량) 범주형 데이터
- 2차원 데이터 분석할 경우 두변수간의 관련성을 확인하는 것이 필요합니다. 범주형 데이터인 경우 교차표, 계량향 데이터인 경우는 상관관계를 구하시면 됩니다.
- 두 변수가 모두 범주형인 경우 교차표를 작성하시면 됩니다. 판다스의 crosstab() 메서드를 사용하시면 됩니다. rmargins=True 옵션을 설정하면 전체 빈도가 표시됩니다.
- normalize='all' 옵션을 설정하면 전체 백분율이 표시됩니다. 만약 행백분율을 구하고 싶으면 normalize ='index', 열 백 분율을 구하고 싶으면 normalize='column'이라고 지정하면 됩니다.
|
print(pd.crosstab(df_cat['sex'], df_cat['psyt'], margins=True)) # 빈도 확인
print(pd.crosstab(df_cat['sex'], df_cat['psyt'], margins='all')) # 전체 백분율확인
print(pd.crosstab(df_cat['sex'], df['psyt'], normalize='index')*100) #행백분율 확인
|
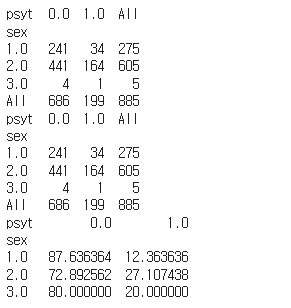
반복문을 이용하여 모든 범주형 데이터에 대한 교차분석을 실시하였습니다.
|
for col in df_cat.columns :
print(col)
print(pd.crosstab(df_cat[col], df_cat['psyt'], normalize='index')*100) #행백분율 확인
print("=================================")
|
(4) 2차원(다변량) 계량형 데이터
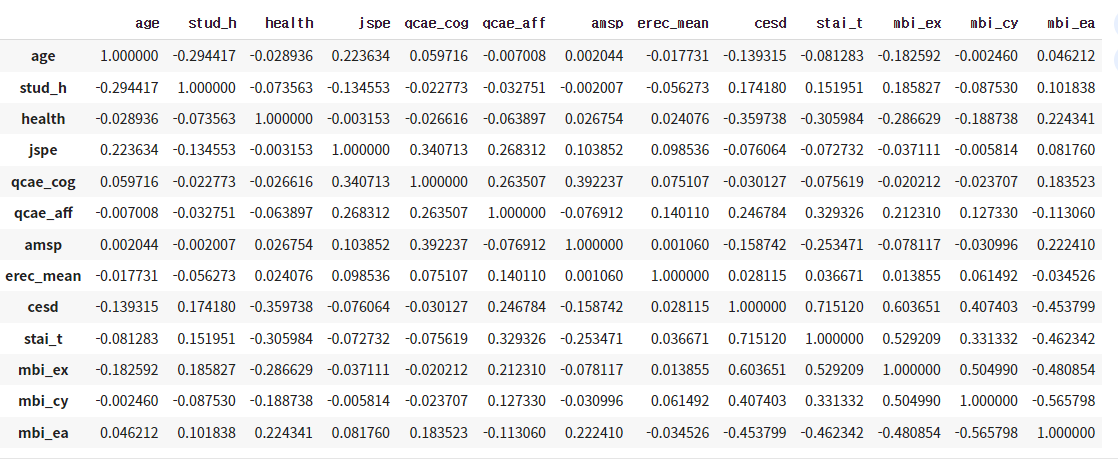
- 2차원 계향형 데이터의 두 변수 간의 선형적 관계를 상관 계수로 표현하는 것 입니다. 상관계수는 -1에서 1 사이 값을 가지며 절댓값 1에 가까울수록 선형관계가 높습니다.
| df_num.corr() |
(4) 복합 데이터 탐색
- 범주형 데이터와 계량형 데이터가 혼합되어 분석할 경우 복합데이터라고 합니다.
|
print("불안감", df['stai_t'].groupby(df['psyt']).mean(), "피로", df['mbi_ex'].groupby(df['psyt']).mean(), "냉소", df['mbi_cy'].groupby(df['psyt']).mean(), "전문적 효능감", df['mbi_ea'].groupby(df['psyt']).mean())
|

(5) 분석할 데이터 셑 생성
분석할 데이터는 계량형 데이터 중 우울증, 불안감, 피로감, 냉소, 직무적 효능감이고, 범주형 데이터는 성별, 학년, 심리적 치료여부, 직업여부로 지정하고자 합니다. 그리고 계량형데이터 셑과 범주형데이터 셑을 통합한 데이터 셑 이름은 df_data 입니다.
|
#cesd : 우울증, stai_t : 불안감, mbi_ex : 피로감, mbi_cy : 냉소 , mbi_ea : 효능감
df_num_data=df_num[['cesd', 'stai_t', 'mbi_ex', 'mbi_cy', 'mbi_ea']] #계량형 데이터
df_cat_data=df_cat[['sex', 'year', 'psyt', 'job']] #범주형 데이터
df_data=pd.concat([df_num_data, df_cat_data], axis=1) #통합
df_data.head()
|
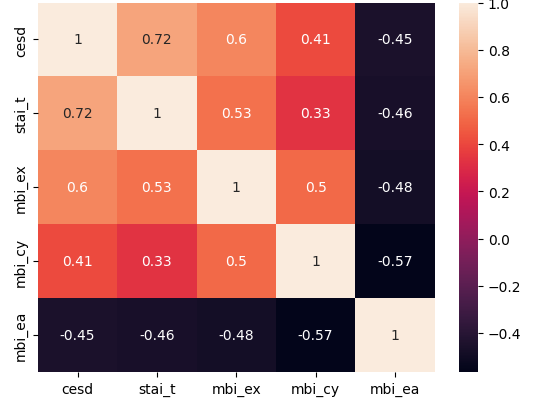
계량형 데이터에 대한 상관계수의 heatmap을 그려봅니다.
|
df_num_corr = df_num_data.corr()
sns.heatmap(df_num_corr,annot = True)
|
4. 데이터 탐색(시각화)
(1) 히스토그램
우울증에 대한 히그토그램을 그려봅니다.
|
#데이터 시각화(히스토그램)
plt.hist(df_num_data['cesd'], bins=25, color = 'darkcyan')
plt.title('cesd Histgram')
plt.show()
|
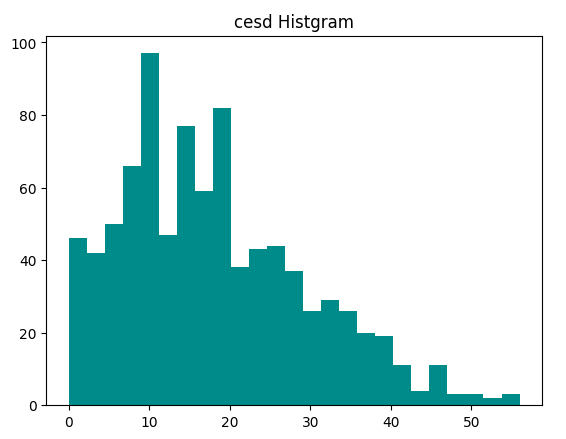
|
for col in df_num_data.columns :
plt.hist(df_num_data[col], bins=15, color = 'darkcyan')
plt.title(col + ' Histgram')
plt.show()
|
(2) 상자그램
|
#데이터 시각화
plt.boxplot(df_num_data['cesd'], vert=False)
plt.title('cesd boxbplot')
plt.show()
|
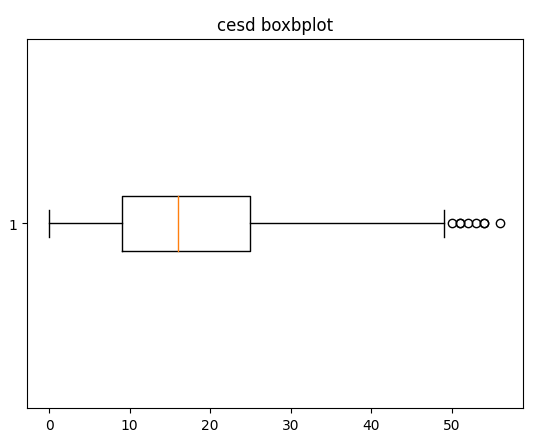
반복문을 이용하여 boxplot를 표시한 내용입니다.
|
for col in df_num_data.columns :
plt.boxplot(df_num_data[col], vert=False)
plt.title(col + ' boxplot')
plt.show()
|
seaborn을 이용하여 차트를 그려봅니다.
|
sns.histplot(df_num_data, kde=True)
|
|
sns.boxplot(df_num_data)
|
'데이터이야기' 카테고리의 다른 글
| 분류모형을 이용한 은행 고객 이탈 모형(02) (0) | 2023.11.14 |
|---|---|
| 분류모형을 이용한 은행 고객 이탈 모형 (1) | 2023.11.13 |
| 데이터로 보는 고령자 디지털 정보 역량 군집화와 디지털 격차 해소 방안 (0) | 2023.10.09 |
| 데이터로 보는 고령자 디지털 격차 데이터전처리, 데이터탐색, 데이터시각화 (0) | 2023.10.03 |
| 데이터로 보는 고령자 디지털 격차 (0) | 2023.09.25 |