반응형
한국지능정보사회연구원에서는 매년 디지털정보격차 실태조사를 실시합니다. 실태조사한 원본데이터를 활용하여 고령자의 디지털 격차를 확인해 보고, 방안을 제시하고 합니다.
실습에 사용될 데이터 파일은 https://github.com/sense64/data_viz/tree/main/data에 제공되고 있으며, 이중 sinor_data.xlsx 파일을 다운로드합니다.

1. 데이터 불러오기
- 판다스의 read_excel() 메서드를 메서드를 이용하여 파일을 불러옵니다. head() 메서드를 이용하여 데이터를 확인합니다.
|
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_excel("/content/drive/MyDrive/old_wellbing/sinor_data.xlsx")
df.head()
|
참고 : 실습환경은 colab이고, 파일경로는 colab에 업로드한 파일경로입니다.
- 아래의 표는 주요 변수 설명입니다.
| 변수 | 변수설명 |
| Q5 | 모바일역량 |
| Q8 | 검색 및 이메일 |
| Q9 | 샤회관계서비스 |
| Q10 | 생활서비스 |
| Q11 | 정보생산 |
| Q12 | 네트워킹 |
| Q13 | 사회참여 |
| Q14 | 경제활동 |
| AGE | 연령 |
| GENDER | 성별 |
| WAGE | 소득 |
2. 데이터 전처리
- info() 메서드를 이용하여, 데이터 형, 행과 열의 수등 데이터 정보를 확인할 수 있습니다.
|
# 데이터 정보를 확인
df.info()
|
- isnull().sum() 함수를 이용하여 결측치 여부를 확인합니다. 만약에 결측치가 있을 경우, 해당하는 case를 삭제하던지, 다른 값으로 대체하셔야 합니다. 데이터 전처리과정은 여기에서 참조하세요.
|
#데이터 전처리 과정(결측치 여부)
df.isnull().sum()
|
3. 데이터 탐색
- 데이터 척도에 따라 구분해야 됩니다
- 범주형 데이터는 표와 그림으로 정리요약을 할 수 있습니다.
- 계량형 데이트는 표, 그림 그리고 숫값(대푯값, 산포도)으로 정리요약할 수 있습니다.
(1) 1차원 데이터 탐색
- 범주형 데이터
- 1차원 범주형 데이터 표로 정리요약은 value_counts() 메서드를 사용하면 빈도를 구할 수 있고, vlaue_counts( normalize=True) 은 비율을 구할 수 있습니다. 아래 출력결과를 보면, 60대가 46.95%로 가장 비중이 높게 나옵니다.
|
#1차원 범주형데이터 표로 정리요약
print(df['age'].value_counts()) #빈도를 확인
print(df['age'].value_counts(normalize=True)*100) #비율을 확인
|

- 반복문을 이용하여 모든 범주형 데이터의 빈도분석을 한꺼번에 처리할 수 있습니다. 결과를 보고, 데이터를 수정할 것이 있는지 확인해 봅니다.
|
#반복문을 이용하여 모든 범주형 데이터의 빈도분석을 한꺼번에 처리
for col in df_cat.columns :
print(col)
print(df[col].value_counts())
print(df[col].value_counts(normalize=True)*100)
print("=================================")
|
- 출력결과를 확인하니 소득이 높은 케이스가 많지 않아, 소득이 7, 8, 9, 10, 11은 하나로 묶어서 처리하도록 하겠습니다.

|
w=[]
for data in df['wage']:
if data==1 or data==2 or data==3 or data==4 :
w.append(data)
elif data==5 or data==6 :
w.append(5)
else :
w.append(6)
df['w'] =pd.DataFrame(w)
df_cat['w'] =pd.DataFrame(w)
|
- 데이터를 수정하고 출력한 결과입니다.

- 계량형 데이터
- 1차원 계량형 데이터는 숫값으로 정리 요약은 describe() 함수를 사용하면 됩니다. 아래의 결과를 살펴보면 평균, 표준편차, 최솟값, 제1사분위수, 제2사분위수, 제3사분위수, 최댓값을 확인할 수 있습니다. 고령자는 디지털활용 역량 점수가 가장 낮은 항목은 무엇인가? 향후 연령별, 성별, 소득별로 구분하여 상세분석을 진행할 수 있습니다.
|
df_num.describe()
|

(2) 2차원 데이터 탐색
- 2차원 데이터 분석할 경우 두변수간의 관련성을 확인하는 것이 필요합니다. 범주형 데이터인 경우 교차표, 계량향 데이터인 경우는 상관관계를 구하시면 됩니다. 가설검정은 여기를 클릭하세요.
- 범주형 데이터
- 두 변수가 모두 범주형인 경우 교차표를 작성하시면 됩니다. 판다스의 crosstab() 메서드를 사용하시면 됩니다. rmargins=True 옵션을 설정하면 전체 빈도가 표시됩니다.
- normalize='all' 옵션을 설정하면 전체 백분율이 표시됩니다. 만약 행백분율을 구하고 싶으면 normalize ='index', 열 백 분율을 구하고 싶으면 normalize='column'이라고 지정하면 됩니다.
|
pd.crosstab(df['age'], df['gender'], margins=True) # 빈도 확인
pd.crosstab(df['age'], df['gender'], normalize='all')*100 #전체 백분율 확인
pd.crosstab(df['age'], df['gender'], normalize='index)*100 #행백분율 확인 |
<출력결과>
 |
 |
 |
- 계량형 데이터
- 2차원 계향형 데이터의 두 변수 간의 선형적 관계를 상관 계수로 표현하는 것 입니다. 상관계수는 -1에서 1 사이 값을 가지며 절댓값 1에 가까울수록 선형관계가 높습니다. 아래의 상관계수를 확인한 결과 경제활동디지털 역량과 사회참여 디지털 역량의 상관계수가 상당히 높습니다. 추후 분석이 더 필요할 것 같습니다.
| df_num.corr() |
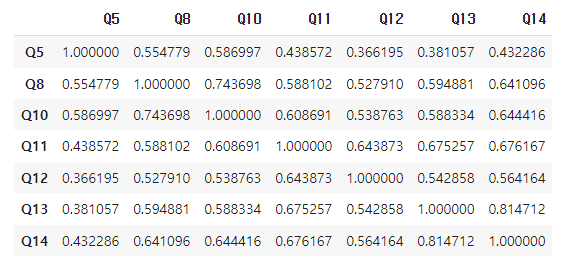
(3) 복합 데이터 탐색
- 범주형 데이터와 계량형 데이터가 혼합되어 분석할 경우 복합데이터라고 합니다. 연령 및 소득에 따른 경제활동 디지털역량과 사회참여 디지털 역량을 확인하도록 하겠습니다.
- 출력결과를 확인하면, 연령이 낮을 수록, 소득이 높을수록, 남자인 경우가 역량이 높은 것으로 조사되었습니다.
|
print("연령별 경제활동", df['Q14'].groupby(df['age']).mean(), "사회참여", df['Q13'].groupby(df['age']).mean())
print("소득별 경제활동", df['Q14'].groupby(df['w']).mean(), "사회참여", df['Q13'].groupby(df['w']).mean())
print("소득별 경제활동", df['Q14'].groupby(df['gender']).mean(), "사회참여", df['Q13'].groupby(df['gender']).mean()
|
참고 : https://github.com/sense64/data_viz/blob/main/senior_digital_00.ipynb
4. 데이터탐색(시각화)
- 시각화하기 전에 사용할 데이터 셑을 정의하도록 하겠습니다. raplace()함수를 사용하여 범주형 데이터의 값을 한글로 변환합니다. 예를 들어 gender 컬럼의 1의 값을 "남자"로 치환하려면 df_cat= df_cat.replace({'gender' : 1}, "남자") 로 코드하시면 됩니다.
|
df_cat= df_cat.replace({'gender' : 1}, "남자") #gender 컬럼의 1의 값을 "남자"로 치환
df_cat = df_cat.replace({'gender' : 2}, "여자")
df_cat = df_cat.replace({'age' : 1}, "50대")
df_cat = df_cat.replace({'age' : 2}, "60대")
df_cat = df_cat.replace({'age' : 3}, "70대이상")
df_cat = df_cat.replace({'w' : 1}, "100만원미만")
df_cat = df_cat.replace({'w' : 2}, "100만원대")
df_cat = df_cat.replace({'w' : 3}, "200만원대")
df_cat = df_cat.replace({'w' : 4}, "300만원대")
df_cat = df_cat.replace({'w' : 5}, "400-500만원대")
df_cat = df_cat.replace({'w' : 6}, "600만원이상")
df_cat.head()
|
- df_num은 계량형 데이터프레임 데이터 셑이고, df_cat은 범주형 데이터 셑 입니다. 두 데이터 셑을 합하기 위해서는 concat()함수를 사용하며, axis=1은 합칠때 열방향으로 합하게 됩니다. index을 기준으로 innder 조인을 합니다. 최종 사용할 data set의 이름은 data 입니다.
|
data = pd.concat([df_num, df_cat], axis=1, join='inner')
print(data)
|
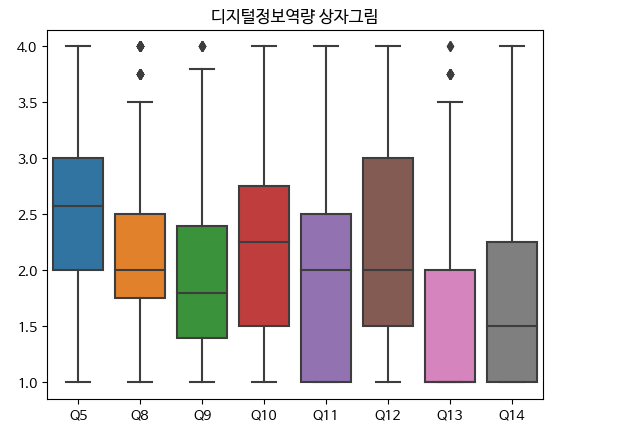
- 분포를 확인하기 위해 가장 많이 사용하는 차트는 boxplot과 histogram입니다. seaborn을 이용하여 boxplot을 그리고자 합니다.
|
sns.boxplot(df_num)
plt.title("디지털정보역량 상자그림")
|
참고 : 한글이 깨어진다면, 글꼴이 설치되지 않아서 입니다.
한글이 깨어져 나오는 것은 한글 폰트가 설치되어 있지 않기 때문에 아래와 같이 한글 폰트를 설치합니다. 그리고 설치된 폰트를 사용하기 위해 [런타임] 메뉴-> 런타임 다시 시작을 하시면 됩니다.한글을 사용하는 경우 아래의 코드를 상단에 위치하는 곳이 좋습니다.
|
#한글이 깨어지는 경우
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
|
matplotlib를 이용하여 사용할 글꼴을 지정해야 차트에 한글이 표시됩니다. 아래의 코드를 반드시 지정하세요.
|
#한글 폰트를 사용
plt.rc('font', family='NanumBarunGothic')
|
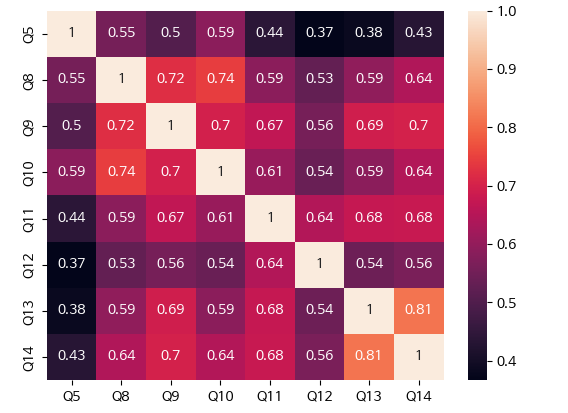
- 히트맵을 이용하여 계량형 두 변수가간의 선형관계를 확인할 수 있습니다.
|
df_num_corr = df_num.corr()
sns.heatmap(df_num_corr,annot = True)
|
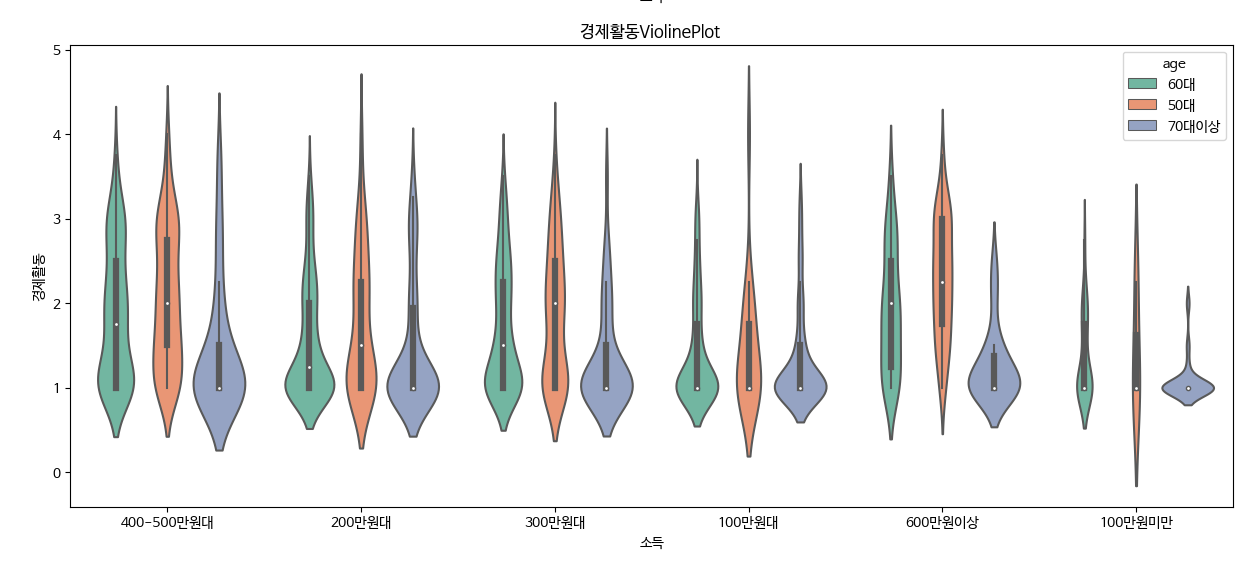
- 아래와 같이 코드를 하면 고령자 디지털 역량지수를 모두 확인할 수 있습니다. 아래의 그림을 보고 설명하세요.
|
dic = {'역량': 'Q5', '검색 및 이메일' : 'Q8', '사회관계서비스': 'Q9', '생활서비스': 'Q10', '정보생산': 'Q11', '네트워킹':'Q12', '사회참여': 'Q13', '경제활동': 'Q14'} #딕셔너리로 정의
for key, val in dic.items() : #한꺼번에 violinplot을 그리기 위해 for문사용
plt.figure(figsize=(15, 6))
sns.violinplot(x="w", y=val, hue="age", data=data, palette="Set2")
plt.xlabel("소득")
plt.ylabel(key)
plt.title( key + 'ViolinePlot ')
plt.show()
|
소스 : https://github.com/sense64/data_viz/blob/main/senior_digital_01.ipynb
작성일자 : 2023년 10월 3일
'데이터이야기' 카테고리의 다른 글
| 분류모형을 이용한 은행 고객 이탈 모형(02) (0) | 2023.11.14 |
|---|---|
| 분류모형을 이용한 은행 고객 이탈 모형 (1) | 2023.11.13 |
| 데이터로 보는 고령자 디지털 정보 역량 군집화와 디지털 격차 해소 방안 (0) | 2023.10.09 |
| 데이터로 보는 고령자 디지털 격차 (0) | 2023.09.25 |
| 필수업무종사자에 관한 이야기 (0) | 2022.07.26 |