1. 협업 필터링 추천 시스템
협업 필터링 추천시스템은 사용자들의 취향 정보를 기반으로 개별 사용자가 선호라 것 같은 아이템을 예측해서 추천해주는 기술입니다. 이는 사용자의 개인정보나 아이템 정보가 없어도 추천할 수 있습니다. 협업필터링은 최근접 이웃(KNN : K-Nearest Neighbor)과 잠재요인(Latent Factor) 방식이 있습니다. 최근접 이웃(KNN)에는 사용자 기반 CF와 아이템 기반 CF로 구분됩니다. 사용자 기반 협업 필터링은 사용자의 구매 패턴과 유사한 사용자를 찾아서 추천해주는 것이고, 아이템 기반 협업 필터링은 사용자들이 부여한 평점들의 분포가 유사하게 나타난 아이텐을 찾아 추천해주는 것입니다.

2. 코사인 유사도(Cosine Similarity)
코사인 유사도는 벡터간의 얼만 유사한지를 측정하는 수치로 문서 유사도 또는 추천시스템에서 많이 활용되고 있습니다. 벡터의 방향이 비슷할수록 서로 유사하고 유사도 값이 1에 가까워지고, 벡터의 방향이 반대가 될수록 두 벡터는 반대의 관련성을 가지며 유사도 값은 -1에 가까워집니다. 벡터 방향이 90도일때는 두벡터간의 관련성이 없으며 유사도 값은 0에 가깝습니다.
코사인 유사도의 공식은 아래와 같습니다.
3. 사용자 기반 협업 필터링
사용자 기반 협업 필터링(User-Based Collaborative Filtering)은 특정 사용자가 좋아했던 항목을 다른 유사한 사용자의 평가를 통해 추천해 주는 방식입니다. 아래의 표는 사용자-아이템 평점 행렬이고, 카페 데이터를 기반으로 사용자 기반 필터링을 통해 사용자 5에게 추천할 메뉴를 정합니다.
| 아메리카노 | 카푸치노 | 에스프레소 | 라테 | |
| 사용자1 | 4 | 5 | 2 | 2 |
| 사용자2 | 5 | 5 | 1 | 1 |
| 사용자3 | 1 | 1 | 4 | 5 |
| 사용자4 | 1 | 2 | 5 | 5 |
| 사용자5 | 5 | 1 |
- 유사도(사용자5, 사용자1) = 0.965
- 유사도(사용자5, 사용자2) = 1.0
- 유사도(사용자5, 사용자3) = 0.428
- 유사도(사용자5, 사용자4) = 0.385
사용자5와 유사도가 가장 높은 사용자는 사용자 2이므로 사용자 2가 높은 평점을 준 카푸치노를 추천합니다.
4. 아이템 기반 협업 필터링
사용자5는 아메리카노에 높은 평점을 주었다. 아메리카노와 다른 메뉴의 유사도를 계산하면 다음과 같다.
- 유사도(아메리카노, 카푸치노) = 0.987
- 유사도(아메리카노, 에스프레소) = 0.495
- 유사도(아메리카노, 라테) = 0.473
사용자 5가 가장 높은 평점을 부여한 아메리카노와 가장 유사도가 높은 카푸치노를 추천합니다.
5. 사용자 기반 협업 필터링 실습
1) 사용자와 카페 아이템에 대한 평점 데이터를 설정합니다.
|
#CF 추천시스템
import pandas as pd
data = {
"user_id": [1,1,1,1, 2, 2, 2, 2, 3, 3, 3, 3, 4, 4, 4, 4, 5, 5],
"items": ["아메리카노", "카푸치노", "에스프레소", "라테", "아메리카노", "카푸치노", "에스프레소", "라테", "아메리카노", "카푸치노", "에스프레소", "라테", "아메리카노", "카푸치노", "에스프레소", "라테", "아메리카노", "에스프레소"],
"rating" :[4, 5, 2, 2, 5, 5, 1, 1, 1, 1, 4, 5, 1, 2, 5, 5, 5, 1]
}
df = pd.DataFrame(data)
print("사용자-메뉴 평점 데이터:")
print(df)
|
2) 사용자-아이템 평점 행렬을 생성합니다.
|
user_item_matrix = df.pivot_table(index="user_id", columns="items", values="rating").fillna(0)
print("\n사용자-메뉴 평점 행렬:")
print(user_item_matrix)
|
- 사용자-아이템 평점 행렬 결과 입니다.
3) 사용자 간 유사도 계산
- 코사인 유사도를 사용하영 유사도를 계산합니다.
|
from sklearn.metrics.pairwise import cosine_similarity
user_similarity = cosine_similarity(user_item_matrix)
user_similarity_df = pd.DataFrame(user_similarity, index=user_item_matrix.index, columns=user_item_matrix.index)
print("\n사용자 간 유사도 행렬:")
print(user_similarity_df)
|
- 코사인 유사도 행렬입니다. 사용자 5와 유사도가 가장 높은 사용자는 사용자 2이고 가장 높은 평점을 준 카푸치노를 추천합니다.
5) 추천 함수 생성
- 특정 사용자를 기반으로 다른 사용자의 평점을 활용하여 추천 메뉴를 계산합니다.
|
def recommend_items(user_id, user_similarity_df, user_item_matrix, top_n=2):
# 해당 사용자의 유사도 벡터 가져오기
similar_users = user_similarity_df[user_id]
print(similar_users)
# 다른 사용자들의 평점 가중치 계산 (유사도 * 평점)
weighted_ratings = similar_users.values @ user_item_matrix.values
# 사용자가 이미 평가한 항목은 제외
user_ratings = user_item_matrix.loc[user_id]
already_rated = user_ratings[user_ratings > 0].index
recommendations = pd.Series(weighted_ratings, index=user_item_matrix.columns).drop(already_rated)
# 평점이 높은 순으로 정렬
recommendations = recommendations.sort_values(ascending=False)
return recommendations.head(top_n)
# 사용자 5에게 추천
print("\n사용자 1에게 추천된 메뉴:")
print(recommend_items(user_id=5, user_similarity_df=user_similarity_df, user_item_matrix=user_item_matrix))
|
- 사용자 5에게는 카푸치노 메뉴를 추천합니다.

사용자 기반 협업필터링은 비슷한 취향을 가진 사용자들이 좋아했던 아이템을 추천하는 것으로, 새로운 고객에게 유사한 고객의 선호도를 기반으로 아이템을 추천할 수 있습니다.
6. 아이템 기반의 협업 필터링 실습
1) 데이터와 사용자_아이템 평점 행렬은 사용자 기반의 협업 필터링 사례와 동일합니다. 아이템 기반의 협업 필터링을 위하여 아이템 간의 코사인 유사도를 계산합니다.
|
#아이템 기반 협업 필터링 아이템간의 유사도를 계산합니다.
from sklearn.metrics.pairwise import cosine_similarity
# 메뉴 간 코사인 유사도 계산
item_similarity = cosine_similarity(user_item_matrix.T) # 행렬을 전치하여 메뉴를 기준으로 유사도 계산
item_similarity_df = pd.DataFrame(item_similarity, index=user_item_matrix.columns, columns=user_item_matrix.columns)
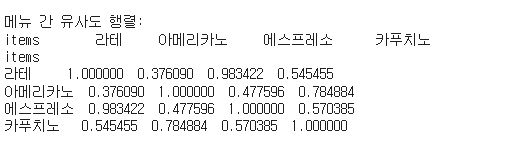
print("\n메뉴 간 유사도 행렬:")
print(item_similarity_df)
|
- 코사인 유사도 행렬입니다. 아메리카노와 유사도가 가장 높은 평점은 카푸치노 입니다.
2) 추천 함수를 구현
- 특정 아이템을 입력하면 유사도가 높은 메뉴를 추천합니다.
|
def recommend_similar_items(item, item_similarity_df, top_n=2):
# 특정 메뉴와 다른 메뉴 간 유사도 가져오기
similar_items = item_similarity_df[item].sort_values(ascending=False)
# 자기 자신 제외 후 상위 N개 추천
recommendations = similar_items.drop(item).head(top_n)
return recommendations
# "Americano"와 유사한 메뉴 추천
print("\n'아메리카'와 유사한 메뉴 추천:")
print(recommend_similar_items("아메리카노", item_similarity_df))
|
- 아메리카노와 유사도가 가장 높은 아이템은 카푸치노이다.

- 아이템 기반 협업 필터링은 사용자들이 공통적으로 높게 평가한 아이템들 간의 유사도를 바탕으로 유사한 아이템을 추천합니다. 특정 사용자가 자주 주문한 음료에 대해 유사한 음료를 추천합니다.
'데이터분석 > 추천시스템' 카테고리의 다른 글
| 연관규칙을 이용한 상품 추천(Apriori 알고리즘) (0) | 2023.11.06 |
|---|---|
| 추천시스템에 대한 이해 (0) | 2023.10.12 |